
Here's the thing. AI is the f̶u̶t̶u̶r̶e̶ present. You are already seeing it everywhere without even realizing it. From LanguageTool to Warp terminal to Nextcloud, AI is now integrated into your favorite tools.
But I believe that the future of AI should be private, local, and open source. I want it to be a tool I use, both the other way around.
Thankfully, I am not the only one to have these thoughts. There are numerous open source LLMs out there and new tools are coming up that make it easy to install and run AI locally on your system.
I am experimenting with AI as an end user and will share my experience with you.
For this tutorial, I will show:
- how you can install Ollama and set it up to run various open source LLMs
- how you can set up Open WebUI to use a web-based interface to interact with AI
What is Ollama?
Ollama is a command line based tools for downloading and running open source LLMs such as Llama3, Phi-3, Mistral, CodeGamma and more. It streamlines model weights, configurations, and datasets into a single package controlled by a Modelfile. All you have to do is to run some commands to install the supported open source LLMs on your system and use them.
I like to think of it as a Docker-like tool (wrong analogy, I know). Like Docker fetches various images on your system and then uses them, Ollama fetches various open source LLMs, installs them on your system, and allows you to run those LLMs on your system locally.
You can find the full list of LLMs supported by Ollama here.
Prerequisite
Here are a few things you need to run AI locally on Linux with Ollama.
- GPU: While you may run AI on CPU, it is not going to be a pretty experience. If you have TPU/NPU, it would be even better.
- curl: You need to download a script file from the internet in the Linux terminal
- Optionally, you should have Docker installed on your system if you want to use Open WebUI. Ollama gives you a command line interface for interacting with the AI. Open WebUI provides you a web interface with ChatGPT like experience.
Step 1: Installing Ollama on Linux
new tools are coming provides an official script that can be used on any Linux distribution.
Open a terminal and use the following command:
curl -fsSL https://ollama.com/install.sh | shAs you can see in the screenshot below, it took approximately 25 seconds to install Ollama on Ubuntu for me.
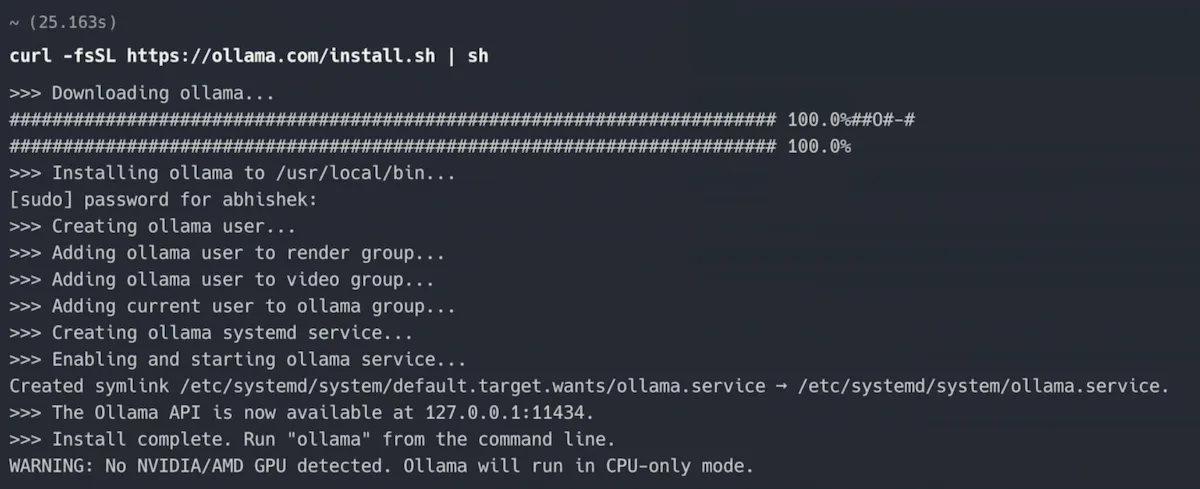
Also note the warning it shows at the end. My Dell XPS has integrated Intel GPU but clearly, Ollama wants NVIDIA/AMD GPU.
In other words, I'll be running AI on CPU only 🤖🔥💻
This is the easy way out. You may go for the manual installation option if you are feeling adventurous.
Check that Ollama is running
Once you have installed Ollama, you should check whether it is running. By default it runs on port number of localhost.
So, open a web browser and enter:
localhost:11434It should show the message, "Ollama is running".
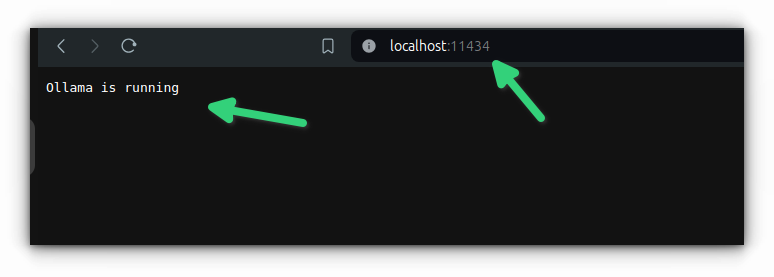
Great! So, you have the tool that could fetch LLMs in your system. Let's see how to do that.
Step 2: Installing LLMs with Ollama
You can "install" your desired LLM in the following manner.
ollama pull <LLM_NAME>As of now, you cannot search for available LLMs from the terminal. You'll have to go to its website. From there, you can get the exact name of the LLM you want to use.
For example, I am going to use llama2, an open source offering from Meta (Facebook).
ollama pull llama2This will take time as it downloads GBs of data. As you can see in the screenshot, it took 2 minutes and 24 seconds to complete for me.

Ollama keeps the LLMs in /usr/share/ollama/.ollama/models directory on Linux. I wanted you to know it.
Great! You have a large language model available now. You have a tool to interact with it. Let's use the AI!
Step 3: Running the AI with Ollama (in terminal)
Run the LLM with this command:
ollama run <LLM_NAME>Since I have installed llama2, I use this command:
ollama run llama2ollama list command.There are no instant greetings that tell you that AI is ready to serve you. You just have to start asking questions to it.
I asked it 'what is itsfoss' but it was not the answer I was expecting.
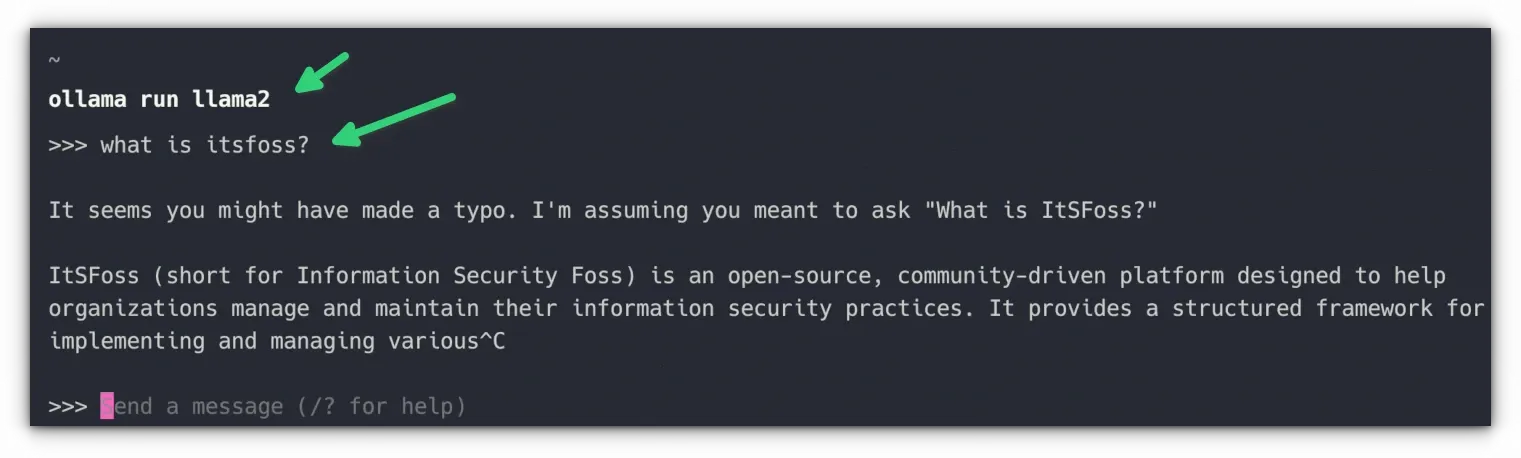
You can use Ctrl+D or type /bye to exit interacting with the AI.
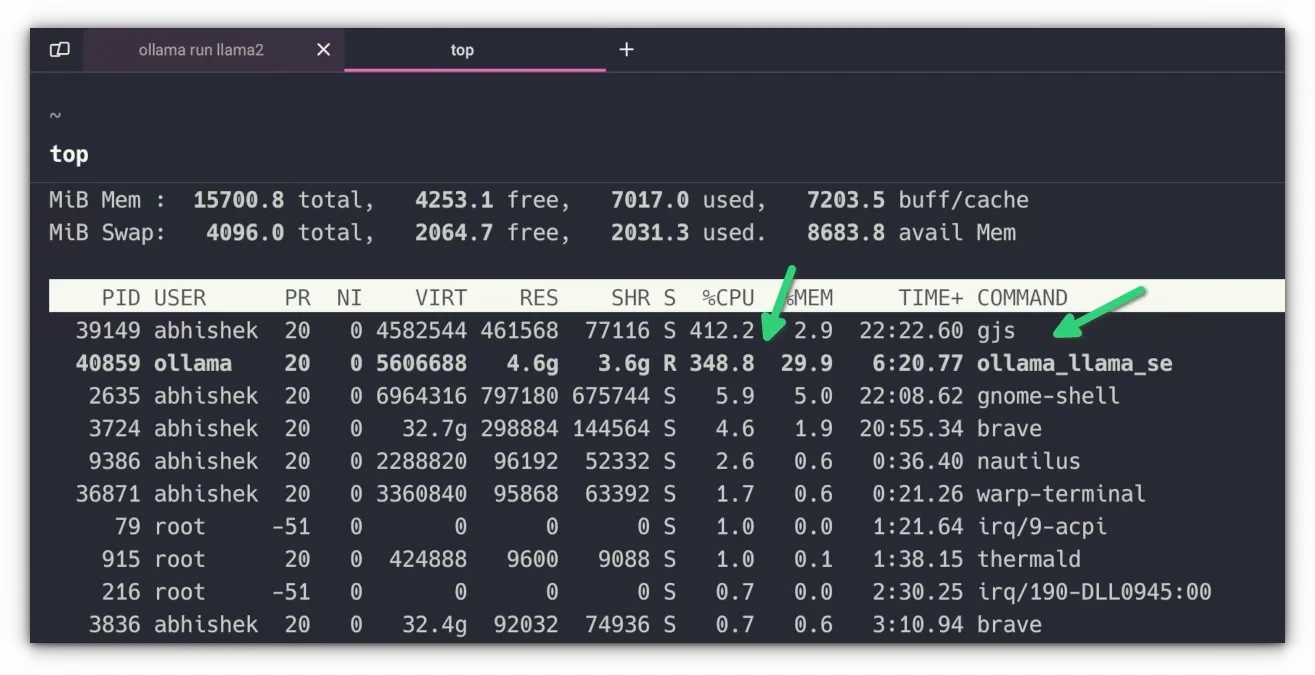
When you start asking a question, you should see a whirring sound. That's the sound of your system going crazy as it consumes all the available resources to run the AI locally. That's why running AI is expensive and not good for the environment.
For me, the response was really slow. It was like using text-based chatting in the early 90s. Words appeared in a stop-motion way. But hey, I am running my own AI without a dedicated GPU or NPU 💪
Optional Step 4: Use AI in ChatGPT like browser interface with Open WebUI
Open WebUI is an open source project that lets you use and interact with local AI in a web browser. If you ever used ChatGPT, Perplexity or any other commercial AI tool, you probably are familiar with this interface.
It's more user-friendly. Your conversations are stored, and you can easily revisit them or even search for them.
Get Docker installed
First, ensure that you have Docker installed on your system.
 Sagar Sharma
Sagar Sharma
Install Open WebUI in Docker
Once Docker is installed on your system, all you have to is run this command as mentioned in the Open WebUI documentation:
sudo docker run -d --network=host -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainThis, too, will take time to download the required docker images and then run the container:
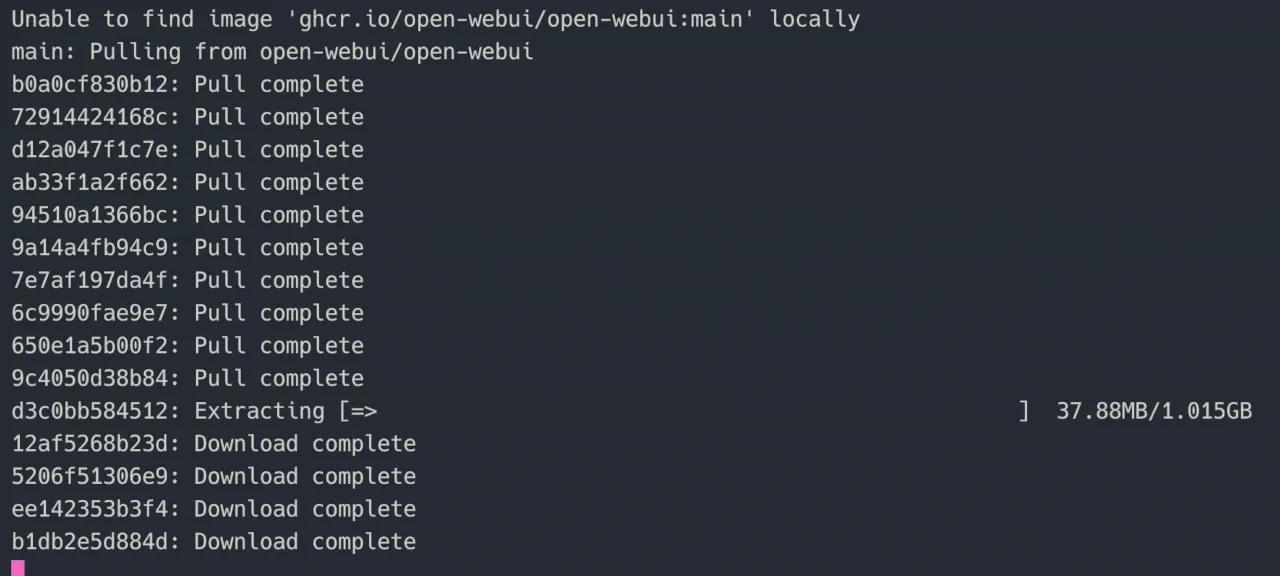
Once the process is completed, make sure that your open-webui container is running by using the docker ps command:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8541f122b75d ghcr.io/open-webui/open-webui:main "bash start.sh" 2 days ago Up 2 days open-webuiRun Open WebUI
Open a browser and access the localhost at port number 8080:
127.0.0.1:8080You'll see a web interface that asks you to create an account.
sudo docker volume rm open-webui but you'll lose all the chat history and existing accounts.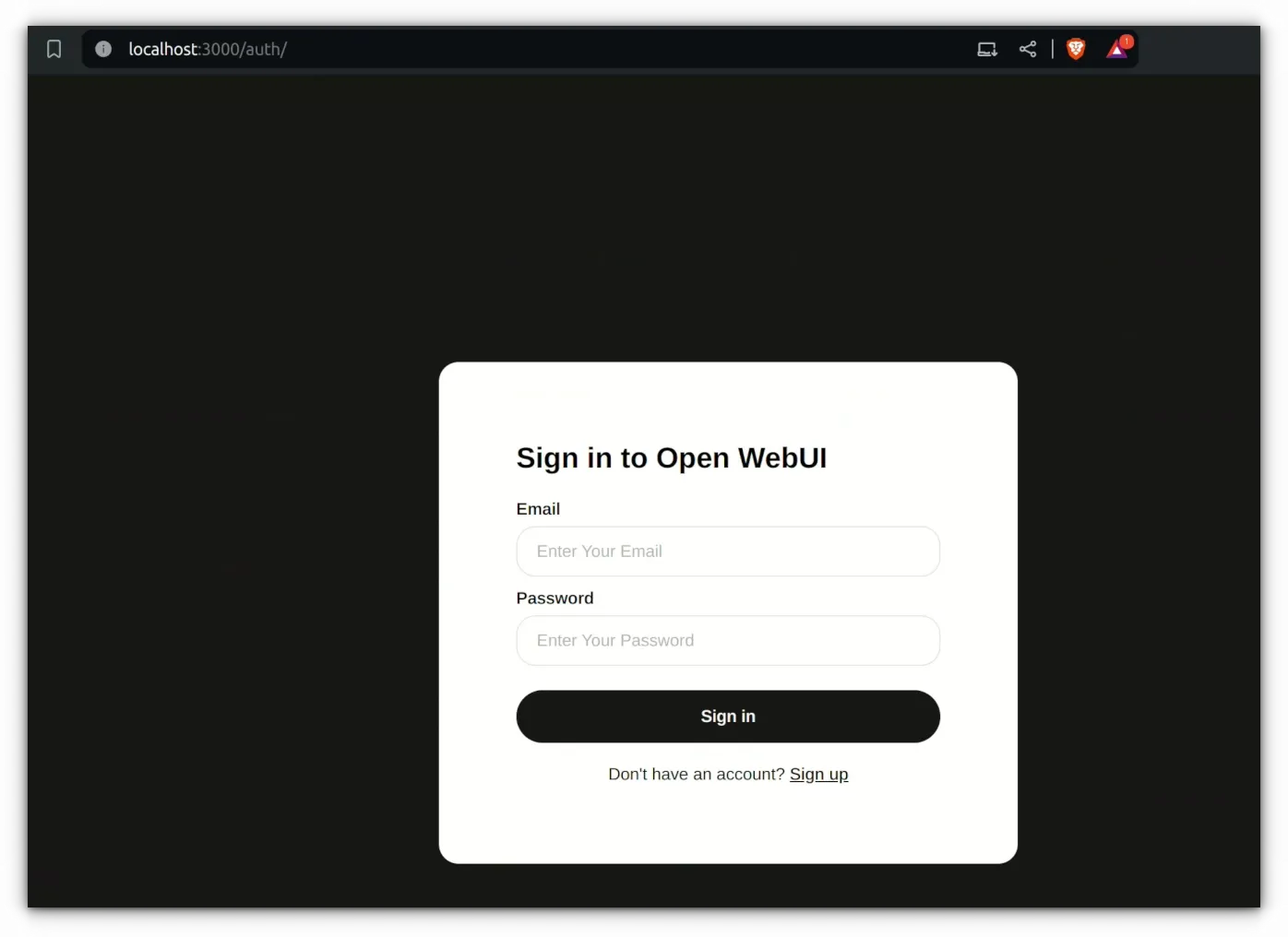
The account you create on the first run is also the admin account. It lets you create more accounts and manage on the same server. This is helpful if you plan to deploy a local AI server which is accessible from other computers on your network.
Once you have logged into the interface, you should click on 'Select a model' and choose the LLMs of your choice. At this point, I had only llama2 installed. If there were more, the choices will be shown here. In fact, you can interact with more than one LLMs at a time in Open WebUI.
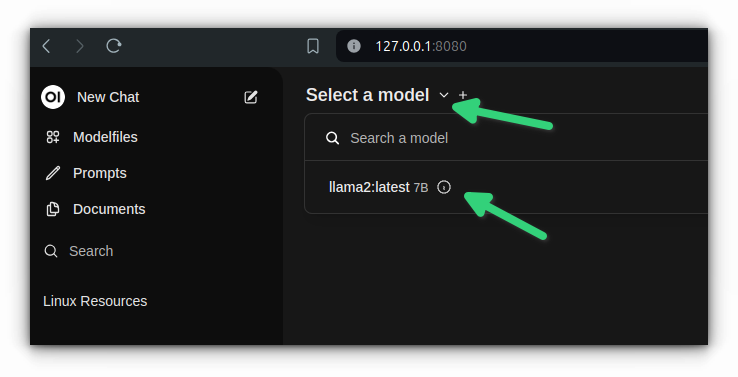
With that, you are ready to interact with it:
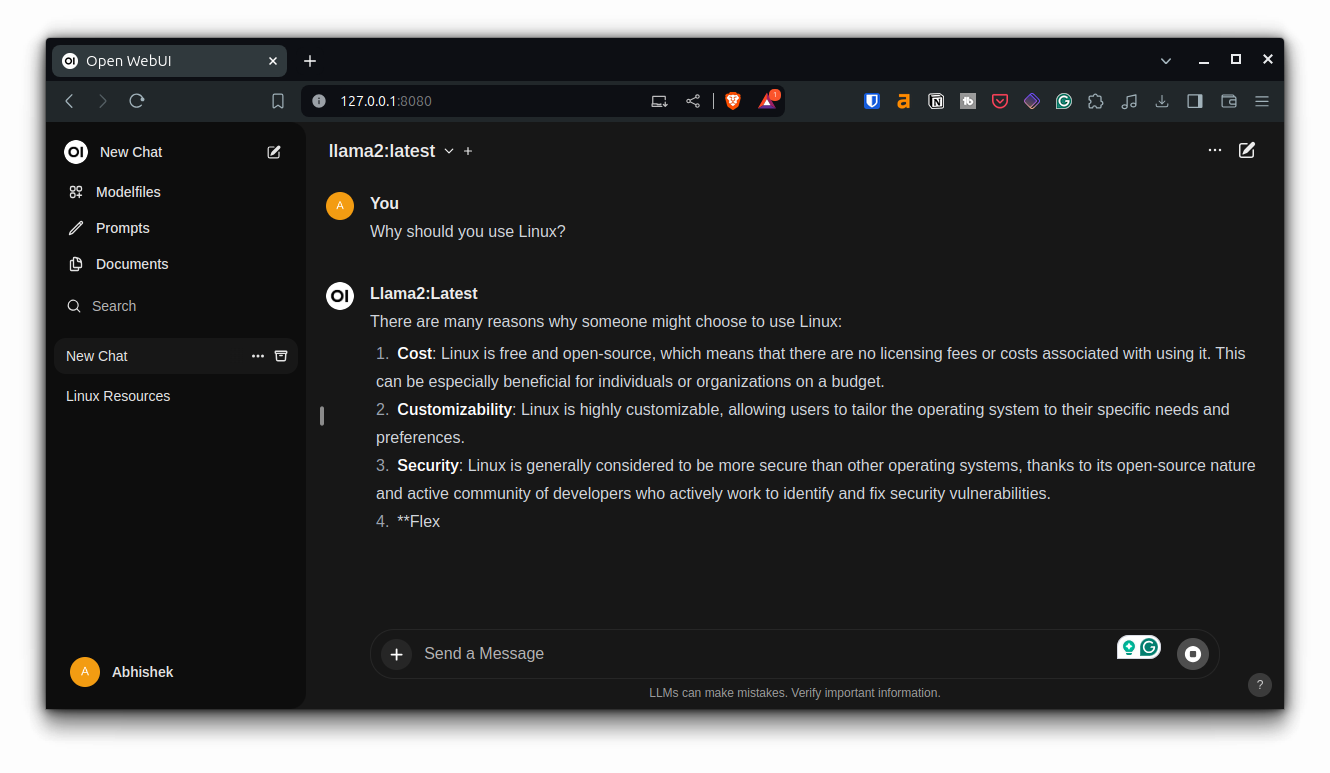
You can edit a response, copy it, give it feedback, read it aloud or regenerate it.
Stop running the AI
When you close the browser tab, your system no longer runs the LLMs and thus your system resource usage comes back to normal.
Keep in mind that Open WebUI container always runs on your system. But it doesn't consume resources unless you start using the interface.
Removal steps
Alright! So you experimented with open source AI and do not feel a real use for it at the moment. Understandably, you would want to remove it from your system and reclaim the disk space.
That's only logical. Let me help you with that.
Removing Open WebUI
If you used Open WebUI, follow these steps.
Stop the running container and then remove it:
docker container stop open-webui
docker container remove open-webuiNext, remove the Docker image as well. List the images with this command:
docker imagesAnd note down the IMAGE ID of the open-webui image and use it in the following fashion:
docker image rm IMAGE_IDYou may also remove the content of /var/lib/docker/volumes/open-webui directory.
I don't see the need to uninstall Docker altogether.
Removing Ollama
Now, let's talk about uninstalling Ollama.
First, list all the LLMs you have installed through Ollama:
ollama listAnd then use its name to uninstall:
ollama rm LLM_NAME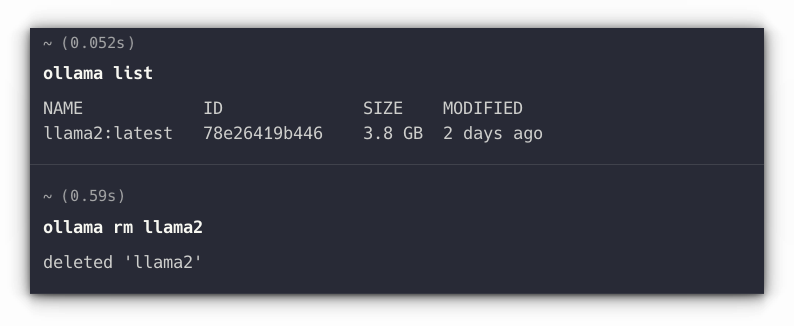
If you missed this step, you can get your disk space back by removing files in the /usr/share/ollama/.ollama/models directory on Linux
With that aside, let's Ollama itself.
Remove Ollama service:
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service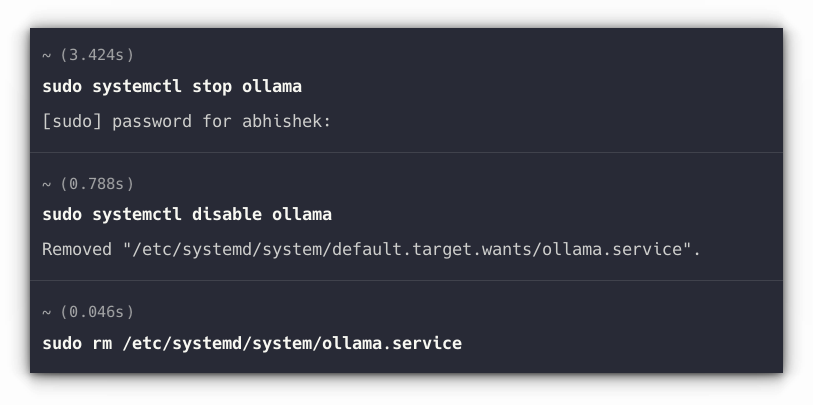
Remove the ollama binary from your bin directory. It could be in /usr/local/bin, /usr/bin, or /bin. So use the command substitution with:
sudo rm $(which ollama)Next, remove the Ollama user and other remaining bits and pieces:
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollamaYou may see a message with userdel 'group ollama not removed because it has other members'. Just ignore it.
Conclusion
As you can see, tools like Ollama make it so easy to install different open source LLMs locally. You can use them for a variety of purpose while keeping it private. From summarizing documents to coding, the usage are numerous and it will only increase in the future.
Of course, your system should be capable enough to run AI like this as it consumes tremendous CPU and GPU. Eventually, NPU (Neural Processing Units) will be available on all modern laptops like GPU these days.
🗨️ Let me know your thoughts about running local AI. And if you face any issues while following this tutorial, do let me know in the comments and I'll try to help you out.
from It's FOSS https://ift.tt/dhoXkix
via IFTTT
Tidak ada komentar:
Posting Komentar